LCX中运行copilot-service
简介
LXC 是一个知名的 Linux 容器运行时,包括各类工具、模板、库以及语言绑定。 它非常底层,相当灵活,并覆盖了上游内核支持的几乎所有与容器相关的功能。copilot-gpt4-service用来帮助我们转发对ChatGPT4的请求。本文记录里怎么在PVE下的LCX中运行copilot-service。
每次当我们写完spark代码后,通过spark-submit命令提交执行。但是这个过程中发生了哪些事情却不甚明了。今天就来看看这个过程中发生了什么。
一切从下边这段提交命令开始:
spark-submit --class org.apache.spark.examples.SparkPi \ |
当我们发现一条SQL语句执行时间过长或者不合预期时,就需要我们对SQL进行优化分析了。怎么找到问题所在呢?
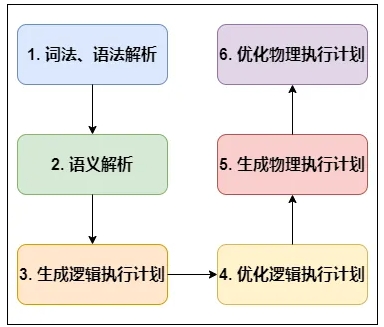
Hive SQL执行计划不像传统关系型数据库Oracle、SQL Server有真实的计划,可以看到各个阶段的处理数据、资源消耗、处理时间等量化数据。Hive的执行计划都是预测的,因此想要知道各个阶段的详细信息,只能查看Yarn提供的日志。日志链接在每个作业执行时给出,可以在控制台看到。
Hive执行计划目前可以查看到:
在SQL语句前加上explain关键词即可查看到执行计划的基本信息,基础的信息包括: