OneData数据治理方法论
简介
onedata体系理论发源于阿里巴巴,目的在于对其庞大业务系统进行中台化管理,期望基于此理论体系构建统一、规范、可共享的全域数据体系,避免数据冗余和重复建设,规避烟囱式建设和不一致性,从而快速响应需求,对外提供高质量数据服务。
传统企业数据管理面临的一些问题
- 数据孤岛,烟囱式重复建设。各个业务部门以自身业务为出发点,为了快速完成相关业务开发,或立足于本业务,完成相关数据模型的设计开发工作。缺少统一的数据服务中心,这必将导致数据孤岛的形成,没有统一的公共层数据服务,也必将导致烟囱式的重复建设。
- 数据不一致。这个问题究其原因,还是视角的问题。对于不一样的业务,其对同一个数据的解读粒度可能就是不一样的。没有统一的数据标准,出现这种情况也几乎是必然的。
- 开发效率差,响应慢。缺少统一的公共层数据支撑,一旦有新的业务需要设计开发,就需要拉齐数据口径,涉及到的数据越多,该过程耗时就越长,开发极其低效,且各业务部门对数据目录的管理情况不一样,不可避免的会出现开发过程中再对其的情景。由此导致非常多的重复性资源消耗。
OneData方法论
针对传统数据管理方式存在的种种弊端,阿里制定了OneData数据治理理论。旨在消除这些不必要的资源损耗,通过构建统一、完整、规范、高质量、可共享的全域数据中心,为其各业务线提供标准化、高可靠性、高质量的数据服务。
架构
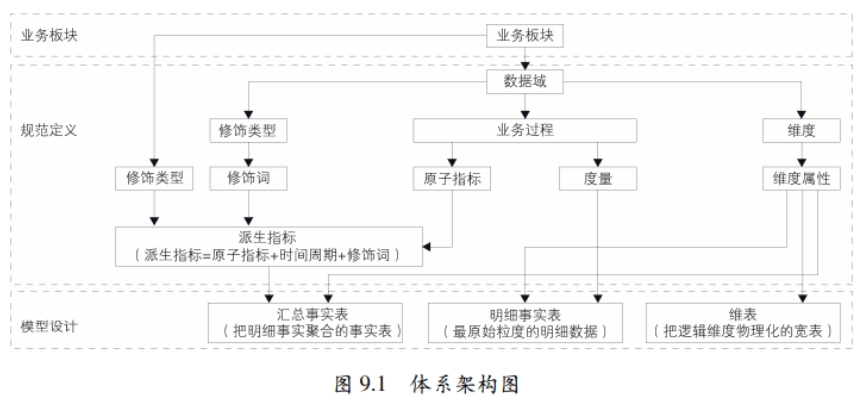
- 业务板块:阿里根据其业务属性的相关性,将业务重叠比较大的业务组织在一起形成一个业务板块。业务板块之间的保持较高的独立性,较低的业务指标重合度。
- 规范定义:根据数仓设计规范,对数据模型进行约束。
- 模型设计:以维度建模理论为基础,构建一致性的维度和事实。在落地时,需要按照规范定义进行实施。
规范定义
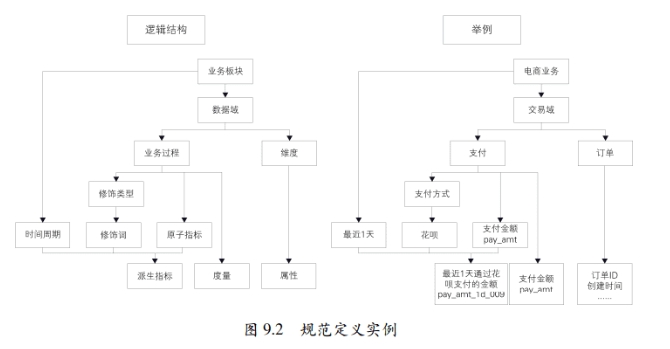
数据域:面向业务,对业务过程或维度进行抽象的集合。
- 业务过程:一个个不可拆分的行为事件。在业务过程之下可以定义指标。
- 维度:指标度量的视角。由一系列维度属性组成。
- 维度属性:如地域维度包含了国家、地区、省市、城市级别等内容。不一样的业务关注的范围不同,则属性不同,从这里也反映出为什么需要一致的维度设计。旨在为全局提供统一的视角,各业务可以在此基础之上针对自身进行维度设计。
对于文章举例的理解,交易域涵盖了支付过程和订单。反过来讲,该域描述的是订单的支付过程,定义订单的维度,是以订单为视角,分析支付过程的一些指标,如过去某段时间内的总成交金额。
修饰类型:对修饰词的抽象划分。举例中的花呗、信用卡、支付宝余额等统称为支付方式。
修饰词:修饰类型的具象化。
时间周期:用来明确数据统计的时间范围或者时间点。
度量/原子指标:某业务事件中具有明确含义,不可拆分的名词。
派生指标:由一个原子指标+时间周期+多个修饰词(可选)组成。可以理解为对一个原子指标圈定业务统计范围。如:最近一天海外买家支付金额。其中支付金额是原子指标,最近一天是时间周期,海外是修饰词。
指标体系
基本原则
组成体系之间的关系
- 派生指标由原子指标、时间周期、修饰词组合得到。
- 原子指标、修饰类型及修饰词,直接归属与业务过程,修饰词继承修饰类型的数据域。
- 派生指标的修饰词之间为“or”或者“and”关系。
- 派生指标唯一归属于一个原子指标,继承原子指标的数据域,与修饰词的数据域无关。
- 原子指标有确定的英文字段名、数据类型、算法说明;
- 派生指标要继承原子指标的英文名,数据类型和算法要求。
命名约定
- 命名所用术语。指标命名尽量使用英文简写,其次是英文,当指标英文名太长,可以考虑使用拼音首字母。
- 业务过程。英文名:用英文或英文缩写或中文拼音简写;中文名:具体业务过程中文即可。
存量指标对应的业务过程约定:实体对象英文名 + _stock。如在线会员数、一星会员数等,其对应的业务过程为mbr_stock;在线商品数、商品SKU种类小于5的商品数等,这种指标对应的业务过程为itm_stock。
- 原子指标。英文名:动作 + 度量;中文名:动作 + 度量。原子指标必须挂靠在某个业务过程下。
- 修饰词。只有时间周期才会有英文名,且长度为2位。如:_1d。
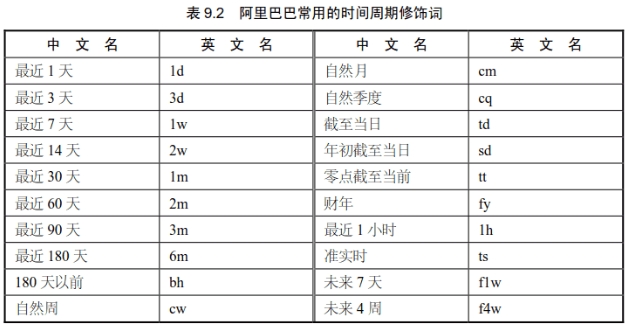
阿里常用的时间周期修饰词:
- 派生指标。英文名:原子指标英文名 + 时间周期修饰词(如:_1d)+ 序号(4位,如:_001);中文名:时间周期修饰词 + [其他修饰词] + 原子指标。
为了控制派生指标的英文名过长,可以将所有修饰词的含义纳入序号中。序号是根据原子指标+派生指标自增的。
算法
原子指标、修饰词、派生指标的算法说明必须保证各种使用人员能看明白,包括:
- 算法概述 — 易于理解的算法阐述。
- 举例 — 指标算法的使用示例。
- SQL算法说明 — 对于派生指标给出SQL的写法或者伪代码。
操作细则
派生指标的种类
事务型指标:是对于业务活动进行衡量的指标。例如:新发商品数、重发商品数、新增注册会员数、订单支付金额,这类指标需维护原子指标及修饰词,在此基础上创建派生指标。
存量型指标:是指对实体对象(如商品、会员)某些状态的统计。例如:商品数、注册会员数、这类指标需维护原子指标及修饰词,在此基础上创建派生指标,对应的时间周期一般为“历史截至当前某个时间”。
复合指标:是在事务型指标和存量指标的基础上复合而成。例如:浏览UV-下单买家转化率,有些需要创建新原子指标,有些则可以在事务型或者存量型原子指标基础上增加修饰词得到。
复合型指标的规则
- 比率型:创建原子指标。如CTR、浏览UV-下单买家数转化率、满意率等。“最近一天店铺首页CTR”,原子指标为”CTR”,时间周期为“最近一天”,修饰类型为“页面类型”,修饰词“店铺首页”。
- 比例型:创建原子指标。如:百分比、占比。例如:“最近一天无线支付金额占比”,原子指标为“支付金额占比”,修饰类型为“终端类型”,修饰词为“无线”,时间周期为“最近一天”。
- 变化量型:不创建原子指标,增加修饰词,在此基础上创建派生指标。例如“最近一天订单支付金额较前一天的变化量”,原子指标为“订单支付金额”,时间周期为“最近一天”,修饰类型为“统计方法”,修饰词为“较上一天变化量”。
- 变化率型:创建原子变量。例如:最近七天海外买家支付金额前七天变化率。原子指标为“支付金额变化率”,时间周期为“最近七天”,修饰类型为“买家地域”,修饰词为“海外买家”。
- 统计型:不创建原子指标,增加修饰词,在此基础上创建派生指标。在修饰类型为“统计方法”下增加修饰词,如人均、日均、行业平均、商品平均、90分位数、70分位数等。例如,自然月日均UV,原子指标为“UV”,修饰类型为“统计方法”,修饰词为“日均”。
- 排名型:创建原子指标,一般为“top_xxx_xxx”,有时会同时选择rank和top_xxx_xxx组合使用。创建派生指标时选择对应的修饰词如下:
- 统计方法(如升序、降序)
- 排名名次(如TOP10)
- 排名范围(如行业、省份、一级来源等)
- 根据什么排序(如搜索次数、PV)
- 对象集合型:主要是指数据产品和应用需要展现数据时,将一些对象以k-v形式存储在一个字段中,方便前端展现。如:趋势图、TOP排名对象等。
其他规则
上下层及派生指标同时存在时
如最近一天支付金额和最近一天PC端支付金额,建议使用前者,将PC端作为维度属性存放在物理表中体现。
父子关系原子指标存在时
当父子关系原子指标存在时,派生指标使用原子指标创建派生指标。如:PV,IPV(商品详情页PV),当统计商品详情页PV时,优先选择原子指标。